
Moving your WordPress uploads directory to the cloud is now as easy as installing the Infinite Uploads plugin and syncing. But a lot is happening under the hood when you add new media to the WordPress library.
Waiting for your files to be optimized, additional sizes to be generated, and then synced to the cloud can take some time and it isn't ideal, especially when bulk uploading media. Infinite Uploads just got a whole lot faster at processing your files.
TLDR; Infinite Uploads now makes 65% fewer cloud API calls and is more than 2x faster when uploading to the WordPress media library!
If you are a nerd like me read on...
The Magic of the PHP Stream Wrapper
Infinite Uploads unlike most other WordPress cloud storage plugins is built around one tiny but pretty amazing piece of technology. When AWS released versions 2 and 3 of their PHP SDK, they included a new yet little-known implementation of a stream wrapper for S3 using the built-in PHP capability for registering custom stream wrappers. For those who are not hardcore PHP developers, here is Amazon's description:
The Amazon S3 stream wrapper enables you to store and retrieve data from Amazon S3 using built-in PHP functions, such as
file_get_contents,fopen,copy,rename,unlink,mkdir, andrmdir.
So basically by registering this custom stream wrapper and changing the location of the uploads directory from a filesystem path like /home/public_html/wp-content/uploads to a custom stream path like s3://bucket PHP will just magically know how to perform all its filesystem actions directly in cloud storage and bypass the local filesystem.
As far as we know the first plugin to pioneer using the AWS S3 stream wrapper was the developer-focused S3-Uploads by Joe Hoyle/Humanmade, who made some minor edits to the AWS provided stream wrapper and a few clever workarounds with WP core hooks to create a working implementation. And it's great, we've used this in the past on large WordPress installs with 22TB+ of storage and 90 million user uploads.
Compatibility, Compatishmility
Most of the cloud storage WordPress plugins out there do not use stream wrappers but instead rely on WordPress hooks to sync files to the cloud after they are saved/modified on the local filesystem. While this can work fine, compatibility with third-party plugins and themes is a support nightmare. Not every plugin that works with the filesystem uses the standard hooks, so plugins like WP Offload Media and Media cloud have to spend untold development hours creating and maintaining custom workarounds for each plugin. Or the third-party plugins have to build custom integrations with them. This is why things like WooCommerce and EDD compatibility are usually only available in the paid or pro license versions of these plugins or sold as add-ons.
In contrast, when using a stream wrapper to replace the local WordPress uploads directory, the cloud connection logic is at a lower level than WordPress itself, so in our experience, 99% of the time plugins just work out of the box. This is why we chose to go the stream wrapper route for Infinite Uploads. Our internal cloud storage APIs are S3 compatible, so we could use their stream wrapper with minor work and provide unparalleled third-party plugin compatibility out of the box.
Efficiency is the Tradeoff
While using the S3 stream wrapper for compatibility is a no-brainer, there is a downside. Every PHP filesystem call that WordPress or plugin's make must be mapped to an API call to the cloud storage provider. So a file_exists() or is_readable() will trigger a HeadObject. unlink() is a DeleteObject. A call to fopen() or file_get_contents() will trigger a GetObject, etc. These API calls have much more latency than the local filesystem as they mean an HTTP roundtrip to the cloud storage provider API.
Additionally, most cloud providers like S3 or Google Cloud Storage charge separately for these API calls, which can really add up. Unfortunately, WordPress and most plugin code is not well optimized to minimize filesystem actions. For example, WP seems to on every request check if the needed date subdirectories exist in the uploads folder. This would be an expensive ListObject API call any time a plugin checks for the path to the uploads directory without our optimizations.
However, with WordPress, 99% of the time code does not need to access the cloud filesystem. Most requests are simply to display images in HTML, which map to GetObject API calls that are proxied and cached by our CDN. The primary time this performance hit is noticeable is when uploading new media to the media library. When you upload an image to the media library, it doesn't just save that one file to disk. The process looks more like this:
- Check filesystem multiple times to find a unique filename
- Save uploaded image
- Open that image to memory for thumbnail generation
- Process the image file into a thumbnail
- Check filesystem multiple times to find a unique filename
- Save the thumbnail
- Repeat 3-20 times depending on theme and original image size
That's a lot of filesystem activity while the user sits there waiting for that progress bar to finish uploading. In practice for the Infinite Uploads plugin and the average image file, with no plugins active, we found that the stream wrapper adds about 50% to media item upload and processing time. So a 20s upload time now becomes 30s. As media uploading doesn't happen that often, we felt that this is an acceptable if not ideal tradeoff for the compatibility and benefits of cloud storage.
Optimizing the AWS PHP SDK S3 Stream Wrapper
With that said, we want Infinite Uploads to be the fastest and most compatible WordPress cloud storage plugin out there. So we embarked on a project to dive deep into the inner workings of the AWS SDK S3 stream wrapper looking to eke out extra performance.
Debugging - You don't know what you don't know
Other than looking at the code, what happens inside the stream wrapper during normal WordPress usage can be a bit of a black box. It just works, but it's not easy to see what cloud API calls it is making and what code is triggering it. So the first step was to instrument the code with debug logging to get an idea of what was happening. Now adding some defines to the wp-config give us a log of all cloud API calls and optionally a paired-down code trace of what triggered it:
define( 'INFINITE_UPLOADS_SW_DEBUG', true );
define( 'INFINITE_UPLOADS_SW_DEBUG_BACKTRACE', true );This gives you some output that looks like this:
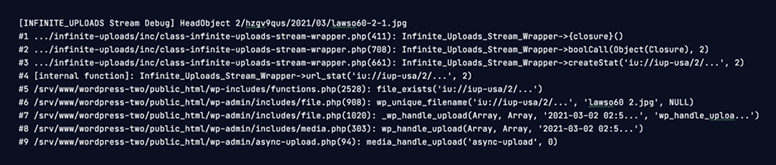
Full Log Example
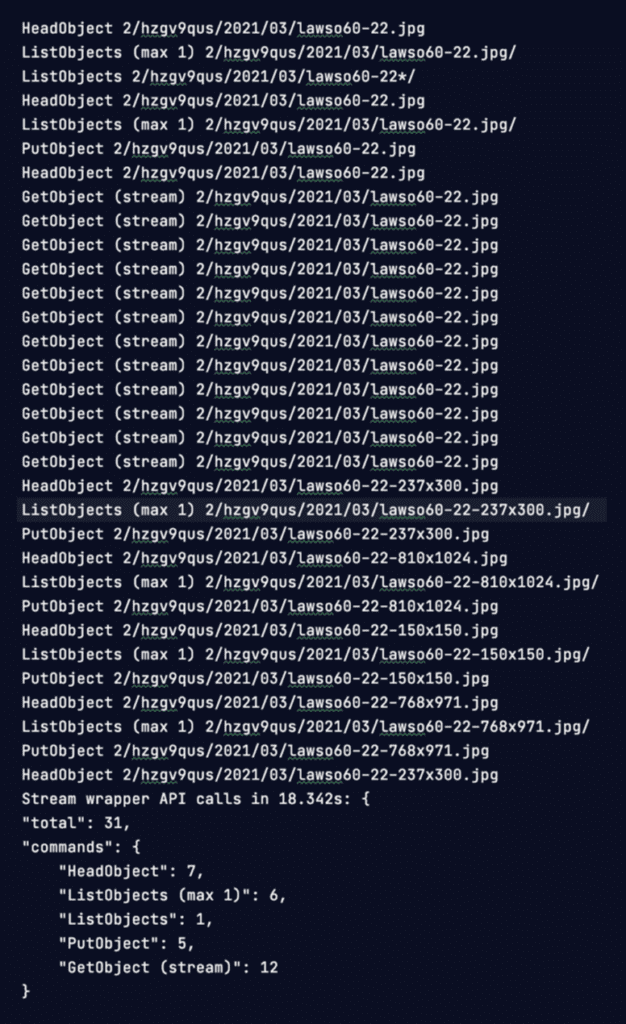
Here is a full example of uploading an image that generates a handful of thumbnails so we can see how many API calls we are making.
We even added a nifty summary that prints at the end of each web request showing the total and a count of each type of S3 API call.
The first thing you might notice is there are a whole lot of duplicated API calls. HeadObject, ListObjects, and GetObject are repeated multiple times for the same files in the same request. Ouch. 😬
Cache the Stat
Well, this should be obvious, absolutely no reason for making duplicate API calls in the same request, let's cache them. The original AWS SDK code by default makes use of a special class called the LruArrayCache which simply stores the latest 1000 cache items in memory via an array during the request. Seeing that that is already implemented, the real question was why are there so many identical API calls? The cache must be getting missed quite often. Time to code another debug logger to see all our cache activity:
define( 'INFINITE_UPLOADS_SW_DEBUG_CACHE', true ); 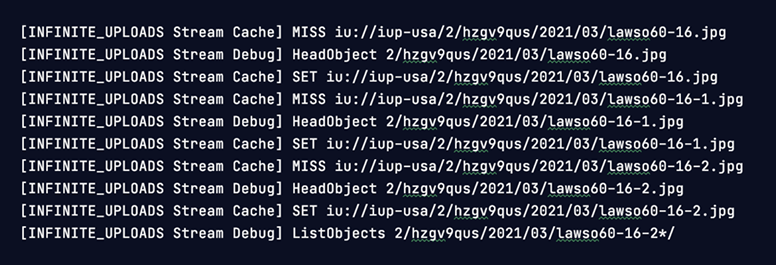
With this info in hand, we could find a lot of places for improvement.
- WP makes a lot of calls to file_exists() when deciding on a unique filename. Non-existent objects and directories were not getting saved to cache. So we fixed that.
- When a file was written to the cloud with PutObject, WP would right away have to fetch filestat info about that file, which meant an extra HeadObject. Since we had the file info handy when uploading it, why not cache it right then? Done.
- Renaming a file would trigger a CopyObject operation. We already know stat details about the copied object, so let's cache those as well with the new filename.
- When a DeleteObject was called like via unlink() or after a rename operation, the code was just clearing the cache key. We know the file is gone, so instead let's cache it as not existing.
Just those simple adjustments pretty much wiped out any duplicate HeadObject API calls in the same request. Nice 👍
Cache the Files
One of the most perplexing behaviors identified by our new debug log was this bit:
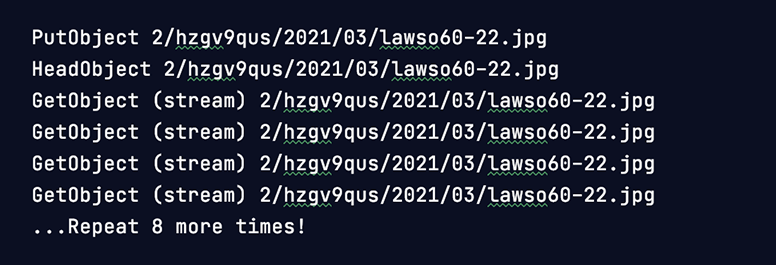
Immediately after WordPress uploads the original image file, it has to immediately download it right back from cloud storage to memory so it can be used to generate thumbnails. What a waste, we just had the file a second before while we pushed it to the cloud. Not to mention this download appeared to be repeated 12 times in a row for the same file. We honestly didn't spend much time digging into why this was as once is already too much.
The obvious solution was to cache the most recently uploaded file in memory so that it can be processed without downloading it again. Because we are uploading and downloading our files as streams (a concept that can be hard to wrap your head around) it took a fair amount of trial and error to figure out how to properly export a copy of the stream as a binary string to store in memory. We also had to take into account available memory for PHP, as some uploaded files can be very large. In the end, we are defaulting to 32MB and that can be changed for systems with low or higher memory via the INFINITE_UPLOADS_STREAM_CACHE_MAX_BYTES define (that's an extra 12 GetObject calls killed).
Ghostly Directories
When you store info on the filesystem, there are two different pointer types, files & directories. This means that to store a file in "X" directory, you have to first create that directory. But in cloud object storage like S3 or Google Cloud Storage (GCS), there really is no such thing as directories, only filenames (keys). So when you store a file like /some/path/file.jpg /some/ and /path/ don't actually exist. This is great for performance and is what allows it to scale to unlimited files as every file can be put on different servers and disks. But it introduces some interesting dichotomies when attempting to map a local filesystem to our cloud filesystem.
To handle this the default AWS SDK stream wrapper for some reason when handling directory operations creates a "ghost" directory by uploading an empty file named for example /some/path/. We're not sure why this is, but it adds a lot of unnecessary overhead. There is no need to create that fake directory. And no need to look for its existence too. This was the main optimization made in the original S3-Uploads plugin, to always force return that the directory exists when WordPress makes its many directory exists checks during upload.
But that didn't go far enough because we can still see inefficiencies when WordPress checks for a non-existent file:

First, it checks if it's a file and if not then it runs a much more expensive ListObjects operation to see if it's not a filename but a directory. There's no need for that in the WordPress media context, so we made a conservative tweak to skip that extra check if the filename has an extension. So far in our tests, we've seen no adverse effects, and that drops off another unnecessary API call.
The Results are In
For our reference medium size image that triggers creation of 4 thumbnails:
- We've dropped 31 API calls to only 11 – That's a 65% reduction in API calls. Which not only speeds things up but reduces cloud transaction costs.
- Average processing time dropped from 14.632 seconds to 6.972 seconds – That's a 52% time decrease!
- The more you generate the more time you save – savings are exponentially greater for images or themes that generate more thumbnails. Or when plugins like WP Smush or Ewww are installed that do post-processing of images.
Media uploads are noticeably faster now, so much so that we've dropped our plans to add a visual "syncing to cloud" indicator when uploading. And we are excited to see how much improvement this makes for other themes and plugins that interact with the uploads directory. It's all gravy!
More Room for Improvement
If you made it this far you may have some other ideas how we can improve stream wrapper efficiency even more. Here is our todo list to look into for the future:
- Persistently cache the file stat cache. Right now the cache is destroyed at the end of the request, so has to be built again on every page request. One example of this is when the Smush plugin processes the image thumbnails asynchronously in a second request right after they are created. Perhaps we can build a custom cache wrapper that uses the built-in WordPress object cache that on better hosts persists across multiple requests. That would increase stat cache hit rates substantially, even with a short timeout.
- Cache the results of GetObject calls. Due to the nature of streams, this is a little bit tricky, but instead of only caching the file from the last PutObject call, it would be smart to also cache when we do a GetObject, in case a plugin needs to open the same file multiple times in the same request.
- Remove the ghost directory functionality completely. There may yet be lots of room for improvements for code that attempts to create directories and check if they exist. Why not just always return that they do as we don't need them anyway?
- With filename conflicts. When there are filename conflicts, use a ListObjects call to check for other names instead of a long loop of incrementing the filename with a number, then performing a HeadObject. This is less common unless uploading the same file multiple times, but every little bit helps.
- Optimize other media actions - when reviewing default media library behavior while doing actions like viewing, editing, and deleting attachments there are more API call patterns that look optimizable. Example when viewing the library in grid mode WP makes a file_exists() and filesize() call for each file to display the size. We can either cache that in postmeta, or lazy load the file size when the attachment is actually opened.
- Gather more real-world performance data for a wider range of plugins. As we get more customers we want to collect debug info from sites that report any possible performance issues and perhaps we will find ways to make Infinite Uploads even faster.
Wrapping It Up
We are committed to making Infinite Uploads the fastest and easiest option when it comes to cloud storage and delivery for WordPress. If you are already an Infinite Uploads user, enjoy the new time saving optimizations when uploading your images starting with version 1.1.2. If you have additional feature requests drop them in the comments or reach out to our support team.
If you haven't tried Infinite Uploads yet, download the Infinite Uploads plugin on the repository and try our services free for 7 days.


